How We Built a Skills Database from Lenny's Podcast Episodes
We turned Lenny Rachitsky's entire podcast archive into 86 actionable skills with downloadable Claude Skills. Here's the full story, including the code.
Part of the Claude topic hub.

Table of Contents
I first met Lenny Ratchitsky in late 2018 as I was walking through South Park in San Francisco. I was peeking through every startup office window as I walked past them and, in one, I saw him speaking to a group of people.
I had recently started following him on Twitter. He hadn’t started his podcast or newsletter back then but he was already well-known in product circles for his Airbnb work.
I walked in after his talk and introduced myself. You can just walk into startup offices in SF if you’re wearing a vest. Lenny was friendly and gracious. We kept in touch and hung out for coffee a couple more times after that. I’m still grateful he took the time, despite his growing fame.
This week, he made all his podcast transcripts openly available. 297 episodes of the best product minds in the world, just sitting there for anyone to learn from. What a great guy.
We decided to do something with it.
The Idea: Skills, Not Chat
Last night, my team and I at Refound, our AI consultancy, brainstormed some ideas for this. What could we do with all this data and information?
We didn’t want to build another chatbot. Lenny already has one. And honestly, chatbots are the most obvious thing you can do with a content library.
But there’s a deeper problem with chat interfaces. They’re great for exploration but terrible for two things:
- Discovery. You don’t know what you don’t know to ask.
- Repeat use. Every conversation starts from scratch, without context.
We wanted something people could apply to their work immediately. What if you could tell stories like April Dunford? Lead people like Brian Chesky? What if all these insights could be where you already work, not in yet another tab or chatbot?
Since we work with AI every day, that meant AI Agents. What if these insights were available as Agent Skills (also known as Claude Skills) that you could install and use while you’re writing docs, prepping for interviews, or planning roadmaps?
And so the Lenny Skill Database idea was born.
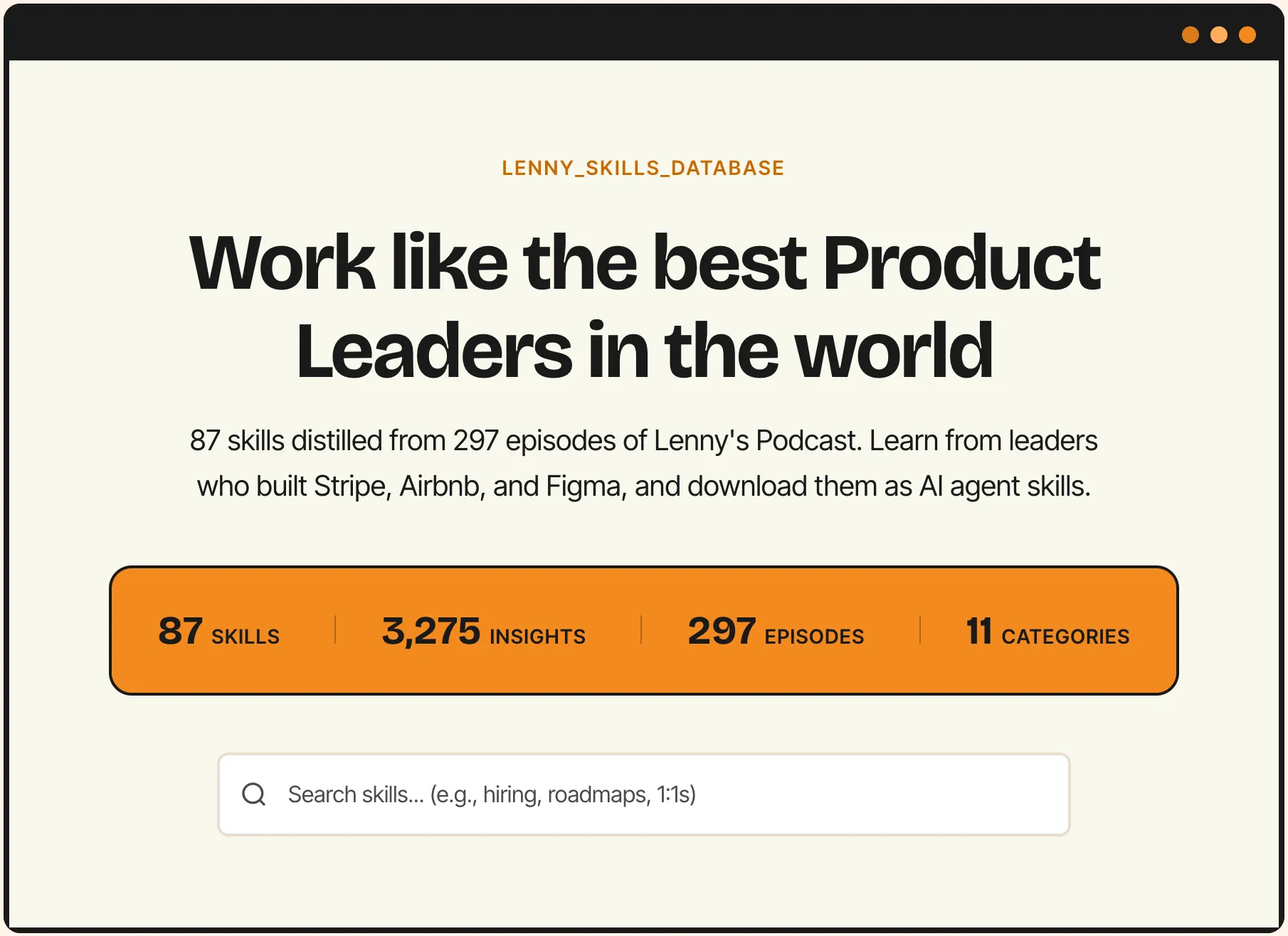
The First Attempt: 5 Hours, $50, and 3,163 Frameworks
Our first approach was simple: extract every “framework” mentioned in the podcast. Named techniques, mental models, tactical advice. An LLM would read each transcript and pull out anything that sounded like a reusable concept.
Here’s the extraction script we used:
SYSTEM_PROMPT = """You are an expert at extracting actionable
frameworks, mental models, and tactical advice from podcast
transcripts. Your goal is to identify insights that are:
1. NAMED or NAMEABLE - Either the guest explicitly names it,
or it's distinct enough to deserve a name
2. ACTIONABLE - Someone could apply this to their work
3. SPECIFIC - Not generic advice like "work hard"
4. ATTRIBUTABLE - Can be tied to a specific quote
Return JSON with: name, type, categories, description,
when_to_use, how_to_apply, quote, timestamp
"""
def extract_frameworks(client, transcript, model="claude-sonnet-4-20250514"):
response = client.messages.create(
model=model,
max_tokens=8000,
system=SYSTEM_PROMPT,
messages=[{
"role": "user",
"content": f"Extract all frameworks from:\n\n{transcript}"
}]
)
return json.loads(response.content[0].text)I ran this overnight. Like an idiot, I did not parallel process. So it ran just one transcript at a time. But I did learn that you can prepend the word caffienated to a bash script and it will keep your laptop from sleeping, so something good came out of that.
About 6 hours later, I woke up to 3,163 extracted frameworks.
| Metric | Value |
|---|---|
| Transcripts processed | 297 |
| Frameworks extracted | 3,163 |
| Average per episode | 10.6 |
| API cost | ~$50 |
| Time | 5 hours |
Here’s what we found after analyzing the output:
# Tag frequency analysis from first extraction
Top 20 Tags:
hiring: 412
culture: 387
growth: 356
leadership: 342
product strategy: 298
career: 276
AI: 245
communication: 234
feedback: 198
decision-making: 187It looked impressive. We had frameworks like “The Keeper Test” (Netflix), “Laughs Per Minute” (Dharmesh Shah), and “Jobs to Be Done” (Bob Moesta). Good stuff.
But when we dug in, we realized it was largely useless.
Why 3,163 Frameworks Didn’t Work
Three problems:
1. Thin content. 97.5% of frameworks had only one guest mentioning them. Most framework “pages” would just be a single person’s quote. Not enough depth to be useful.
# Framework guest distribution
frameworks_by_guest_count = {
1: 3112, # 98.4% - just one guest
2: 35,
3: 12,
4+: 4
}2. Wrong granularity. Nobody wakes up and searches for “24/7 Live Chat Support Framework” or “Team-Based Activation Metrics.” These are too specific to be useful as standalone pages.
3. Poor discoverability. The reason we didn’t want a chatbot was because we wanted people to explore and discover skills. But if you have 3,000 it becomes hard to do so.
The fundamental issue was bottom-up extraction. We were cataloging every named concept, but that’s not how people think. Nobody thinks “I need the Eigenquestions Technique.” They think “How do I prioritize my roadmap?” or “How do I give difficult feedback?”
The Pivot: Jobs to Be Done
As we explored our frameworks data, we noticed something. Many of the frameworks were just specific tactics to accomplish the same underlying task.
Shreyas Doshi might call his prioritization approach something different than Gibson Biddle, but they’re both teaching the same skill: how to prioritize a roadmap.
So we flipped our thinking. Instead of bottom-up extraction (“find every framework”), we’d do top-down extraction (“here are a bunch of skills; find content that matches each one”).
| Aspect | Old (Frameworks) | New (Skills) |
|---|---|---|
| Total items | 3,163 | 86 |
| Guests per item | 1 (98%) | 8-150 |
| User query | ”What is X?" | "How do I do X?” |
| Example | ”Eigenquestions Technique" | "Prioritizing Roadmap” |
This was the right abstraction.
Designing the Taxonomy
Before running any new extraction, we needed to define what we were looking for. This is where our failed frameworks data actually helped. We could see which tags appeared most frequently and cluster them into categories.
Here’s how we structured it:
Hiring & Teams (6 skills)
| Skill | Keywords |
|---|---|
| Writing Job Descriptions | job description, job posting, role description |
| Conducting Interviews | interview process, interview question, screening |
| Evaluating Candidates | hiring decision, reference check, work sample |
| Onboarding New Hires | onboarding, first 90 days, new hire, ramp-up |
| Building Team Culture | team culture, team values, psychological safety |
Product Management (22 skills)
| Skill | Keywords |
|---|---|
| Defining Product Vision | product vision, vision statement, product strategy |
| Prioritizing Roadmap | prioritization, roadmap, backlog, sequencing, RICE |
| Writing PRDs | PRD, product requirements, product spec |
| Problem Definition | problem statement, jobs to be done, JTBD |
| … | |
| And so on. |
We confirmed this by asking Claude to do some data exploration across a few of the transcripts. After a bit of rejigging, we had our final list - (no, this is not an em-dash) 86 skills across 11 categories:
| Category | Skills | Example Skills |
|---|---|---|
| Product Management | 22 | Vision, PRDs, Roadmap, User Research |
| Hiring & Teams | 6 | Interviews, Evaluating Candidates, Culture |
| Leadership | 14 | 1:1s, Difficult Conversations, Delegation |
| AI & Technology | 6 | AI Strategy, Building with LLMs |
| Growth | 6 | PMF, Growth Loops, Pricing |
| Marketing | 6 | Positioning, Storytelling, Launch |
| Communication | 5 | Stakeholder Alignment, Presentations |
| Career | 7 | Career Transitions, Promotion Case |
| Sales & GTM | 7 | Founder Sales, Enterprise, Partnerships |
| Engineering | 5 | Tech Debt, Engineering Culture |
| Design | 2 | Design Systems, Design Reviews |
Of course Lenny’s podcast skews product and leadership, so we were fine with the distribution.
The Extraction Pipeline
With our taxonomy defined, we rebuilt the extraction script. This time with Gemini 3 Flash Preview (fast and cheap), parallel processing (10 workers), and one key addition: asking the LLM to suggest new skills when it finds content that doesn’t fit our taxonomy.
EXTRACTION_PROMPT = """You are extracting structured content
from a podcast transcript for a skills database.
## Your Task
1. Read the transcript carefully
2. Identify ALL sections where the guest discusses any
of the 86 skills below
3. For EACH skill discussed, extract ALL relevant mentions
4. If you find valuable content that doesn't fit any skill,
suggest a new skill
## Skills Taxonomy
{taxonomy}
## Output Format
Return valid JSON:
{{
"matches": [
{{
"skill_slug": "conducting-interviews",
"mentions": [
{{
"quote": "The exact verbatim quote",
"insight": "One sentence summary",
"tactical": ["Actionable advice point 1", "Point 2"],
"timestamp": "00:14:32"
}}
]
}}
],
"suggested_skills": [
{{
"name": "Proposed Skill Name",
"category": "Which category it might belong to",
"reason": "Why this should be a skill",
"quotes": ["Supporting quote 1", "Quote 2"]
}}
]
}}
"""The script handles rate limits with exponential backoff:
def call_api_with_retry(model, prompt, max_retries=5, base_delay=2):
"""Call LLM API with exponential backoff retry."""
for attempt in range(max_retries):
try:
response = model.generate_content(
prompt,
generation_config=genai.types.GenerationConfig(
temperature=0.1,
max_output_tokens=8000,
)
)
return response.text
except Exception as e:
if 'rate' in str(e).lower() or '429' in str(e):
delay = base_delay * (2 ** attempt) # 2, 4, 8, 16, 32
print(f"Rate limited, waiting {delay}s")
time.sleep(delay)
else:
raiseAnd processes transcripts in parallel:
with ThreadPoolExecutor(max_workers=10) as executor:
futures = {
executor.submit(process_transcript, path): path
for path in transcript_files
}
for future in tqdm(as_completed(futures), total=len(futures)):
result = future.result()
# Save progress every 10 transcripts
if processed_since_save >= 10:
save_to_disk(output, progress)
processed_since_save = 0The full script with resumption support, incremental saves, and multi-provider support (Gemini + OpenAI fallback) is about 500 lines. I’ll share the complete version at the end.
What We Got: 3,328 Mentions Across 86 Skills
The new extraction finished in about 15 minutes (vs 5 hours for the old approach). Cost was roughly… free? I think. I’ve never entered my credit card into Gemini’s AI Studio so I have no idea. YOLO.
| Metric | Value |
|---|---|
| Skills | 86 |
| Total mentions | 3,328 |
| Episodes processed | 297 |
| API cost | ~$5… maybe |
| Time | ~15 min |
Top skills by guest coverage:
| Skill | Mentions | Guests |
|---|---|---|
| Building Team Culture | 212 | 138 |
| AI Product Strategy | 179 | 94 |
| Evaluating Candidates | 151 | 94 |
| Defining Product Vision | 143 | 101 |
| Stakeholder Alignment | 124 | 88 |
| Problem Definition | 123 | 91 |
And the suggested skills feature paid off. Gemini proposed 25 new skills that weren’t in our original taxonomy:
| Suggested Skill | Category | Entries |
|---|---|---|
| Developing Product Taste | Product Management | 11 |
| Systems Thinking | Leadership | 6 |
| Product Operations | Product Management | 5 |
| Energy Management | Leadership | 5 |
| Marketplace Liquidity | Growth | 4 |
| User Onboarding | Growth | 4 |
| Vibe Coding | AI & Technology | 3 |
We added all of these to the final database. Final structure: 86 skills across 11 categories.
# Category distribution after cleanup
by_category = {
'Product Management': {'skills': 22, 'mentions': 832},
'Hiring & Teams': {'skills': 6, 'mentions': 479},
'Leadership': {'skills': 14, 'mentions': 463},
'AI & Technology': {'skills': 6, 'mentions': 349},
'Communication': {'skills': 5, 'mentions': 284},
'Growth': {'skills': 6, 'mentions': 279},
'Marketing': {'skills': 6, 'mentions': 265},
'Career': {'skills': 7, 'mentions': 165},
'Sales & GTM': {'skills': 7, 'mentions': 92},
'Engineering': {'skills': 5, 'mentions': 53},
'Design': {'skills': 2, 'mentions': 14},
}Rejigging: Making Skills More Concrete
After the extraction, we did some cleanup. It’s always good practice to explore the results and think about the distribution.
We realized that some skills were too thin, not enough content, while others were too big, with a lot of content. So we rebalanced them a bit.
There are still some skills, like Building Team Culture, with too much content. That being said, team culture is a fairly common theme (no pun intended) in Lenny’s interviews, and the advice is quite cohesive, so I couldn’t think of a great way to break it up into sub-skills. If you can, please let me know.
The Data Model
Our extraction produced an output called skills.json that looks like this:
interface Skill {
name: string;
category: string;
keywords: string[];
entries: Array<{
guest: string;
episode_file: string;
mentions: Array<{
quote: string; // Verbatim from transcript
insight: string; // One-sentence summary
tactical: string[]; // Actionable advice
timestamp: string; // For deep linking
}>;
}>;
guest_count: number;
mention_count: number;
}Here’s an actual entry:
{
"prioritizing-roadmap": {
"name": "Prioritizing Roadmap",
"category": "Product Management",
"guest_count": 75,
"mention_count": 91,
"entries": [
{
"guest": "Shreyas Doshi",
"episode_file": "Shreyas Doshi.txt",
"mentions": [
{
"quote": "The biggest mistake PMs make is trying to prioritize features instead of problems. Features are solutions. You should be prioritizing the problems you're solving.",
"insight": "Prioritize problems, not solutions.",
"tactical": [
"List the top 10 problems your users face",
"Stack rank problems by impact and urgency",
"Only then brainstorm solution options"
],
"timestamp": "00:34:22"
}
]
}
]
}
}So basically, we had quotes from various guests across all podcast episodes speaking about how they do think about that skill, and we combined them all into one overarching skill page.
We then realized that, while the content was informative, it ended up becoming a list of quotes. So we ran each skill through an LLM again and turned it into a more actionable “how-to” guide on using the skill in your daily work.
Playbooks: Curated Skill Collections
Skills are atomic units. But users often need multiple skills for a specific role or workflow. A first-time manager needs 1:1s AND feedback AND delegation. A startup founder needs PMF AND pricing AND founder sales.
So we created 9 cross-category playbooks that combine skills into learning paths:
{
"startup-founder": {
"name": "Startup Founder Playbook",
"tagline": "From zero to product-market fit",
"persona": {
"who": "First-time founders, solo founders",
"stage": "Pre-seed to Series A",
"when": "You're building something new and need PMF"
},
"sections": [
{
"phase": "1. Find the Problem",
"description": "Before building, validate the problem",
"skills": ["problem-definition", "conducting-user-interviews"]
},
{
"phase": "2. Build & Validate",
"description": "Ship the smallest thing that tests your assumption",
"skills": ["scoping-cutting", "measuring-product-market-fit"]
},
{
"phase": "3. Find Growth",
"description": "Figure out how to get more customers",
"skills": ["designing-growth-loops", "pricing-strategy"]
}
],
"key_insight": "80% of early time should be talking to users, not coding.",
"anti_patterns": [
"Building for 6 months before talking to users",
"Hiring senior executives before PMF"
]
}
}The full playbook set:
- Startup Founder (15 skills)
- First-Time Manager (12 skills)
- Product Manager (15 skills)
- Growth Leader (12 skills)
- Engineering Manager (15 skills)
- Sales Leader (12 skills)
- AI Builder (12 skills)
- Executive Communication (12 skills)
- Career Growth (15 skills)
Agent Skills: Making It Actionable
Here’s the real fun part. Creating a page that teaches you a certain skill is great and all. But you’re not going to learn just by reading. We wanted you to be able to apply it to your work right away.
So each skill becomes a downloadable Agent Skill file that you can install in Claude Code, Cursor, or any tool that supports custom skills.
The format:
---
name: prioritizing-roadmap
description: How to prioritize your product roadmap effectively
---
# Prioritizing Roadmap
## What This Skill Covers
- Frameworks for prioritization (RICE, ICE, etc.)
- Problem vs solution prioritization
- Saying no effectively
## Key Insights
### From Shreyas Doshi
> "The biggest mistake PMs make is trying to prioritize
> features instead of problems."
**Tactical advice:**
- List the top 10 problems your users face
- Stack rank problems by impact and urgency
- Only then brainstorm solution options
### From Gibson Biddle
> "The best prioritization frameworks are the ones your
> team will actually use."
**Tactical advice:**
- Pick ONE framework and commit to it
- Revisit priorities quarterly, not weekly
## How to Apply
1. Audit your current roadmap: problems or solutions?
2. Create a problem stack rank with your team
3. For each problem, brainstorm 3+ solution options
4. Pick the highest-leverage solution for each problemNow when you’re working on a product roadmap in Claude, or writing a PRD, you can load this skill and get Shreyas to help you with it, feedback from Gibson, and 73 other expert perspectives right in your document.
Isn’t that cool? I think that’s pretty cool.
What Made This Work
Looking back, a few things were critical:
1. Data exploration and experimentation. Before working with any dataset, it’s important to understand it. I’ve listed to many of Lenny’s episodes, so I have an intuition for them, but I also had Claude explore some of the transcripts to understand what we’re dealing with.
2. Top-down taxonomy, not bottom-up extraction. Defining skills before extraction gave us the right abstraction level. Bottom-up gave us 3,163 scattered items. Top-down gave us 86 useful ones. That being said, I’m glad we started bottoms-up because it allowed us to explore the data more.
3. Testing before scaling. When working with data, you can either use AI agents to transform it, or write scripts that call LLMs to do the same thing. The former allows for exploration while the latter for automation. You can test with agents and then once you’re happy scale it out.
4. Keep iterating. We ran through this loop of data exploration, extraction, testing, and scaling, multiple times. Each time, we learned something new and improved the output. I suppose this is, in a sense, how Lenny’s guests do product.
Try It Yourself
You can replicate this approach for any content library:
- Define your taxonomy. What are the jobs-to-be-done in your domain?
- Explore the data. Understand what you’re dealing with.
- Run extraction. Use the script with your transcripts.
- Review suggested skills. The LLM will find patterns you missed.
- Build playbooks. Group skills for specific personas.
And you can explore the live Lenny Skills Database on the Refound website. In fact, try downloading some of the skills and using it!
And if you build something similar with your own content, I’d love to hear about it. The approach works for any knowledge-dense content: podcasts, YouTube channels, course libraries, internal wikis.
Thanks to Lenny for making his transcripts available, and to Som for the late-night brainstorming sessions that led to this project.
Related Posts

The Ultimate Guide to Model Context Protocol, Part 4: Build Your Own MCP Server
Stop using other people's MCP servers and build your own. A step-by-step Python tutorial that takes you from zero to a working MCP server in under 30 minutes.

AI Killed The CMS: How I Ditched Mine for Code and Markdown
I ditched WordPress for Astro + Markdown. Now my blog is code, deployments are instant, and I've completely transformed my content creation process.

Claude Skills Tutorial: Give your AI Superpowers
Stop repeating instructions. Skills are reusable plugins for Claude that learn your workflows once, then apply them everywhere forever.